proportion power calculation for binomial distribution (arcsine transformation)
h = 0.344372
n = 72.21261
sig.level = 0.05
power = 0.9
alternative = greaterSequential Testing for Experimental Design
Uses of Modern Sequential Testing

Platforms like Statsig implement the SPRT and it is quite easy to use.
AI Deployment Monitoring


- Monitor model quality after deployment
- Detect behaviors in real time without waiting for a fixed \(n\)
- Training: Reinforcement Leanring as a type of experiment
Early Stopping for Clinical Trials

- Stop early for efficacy or futility
- FDA-recommended group sequential designs
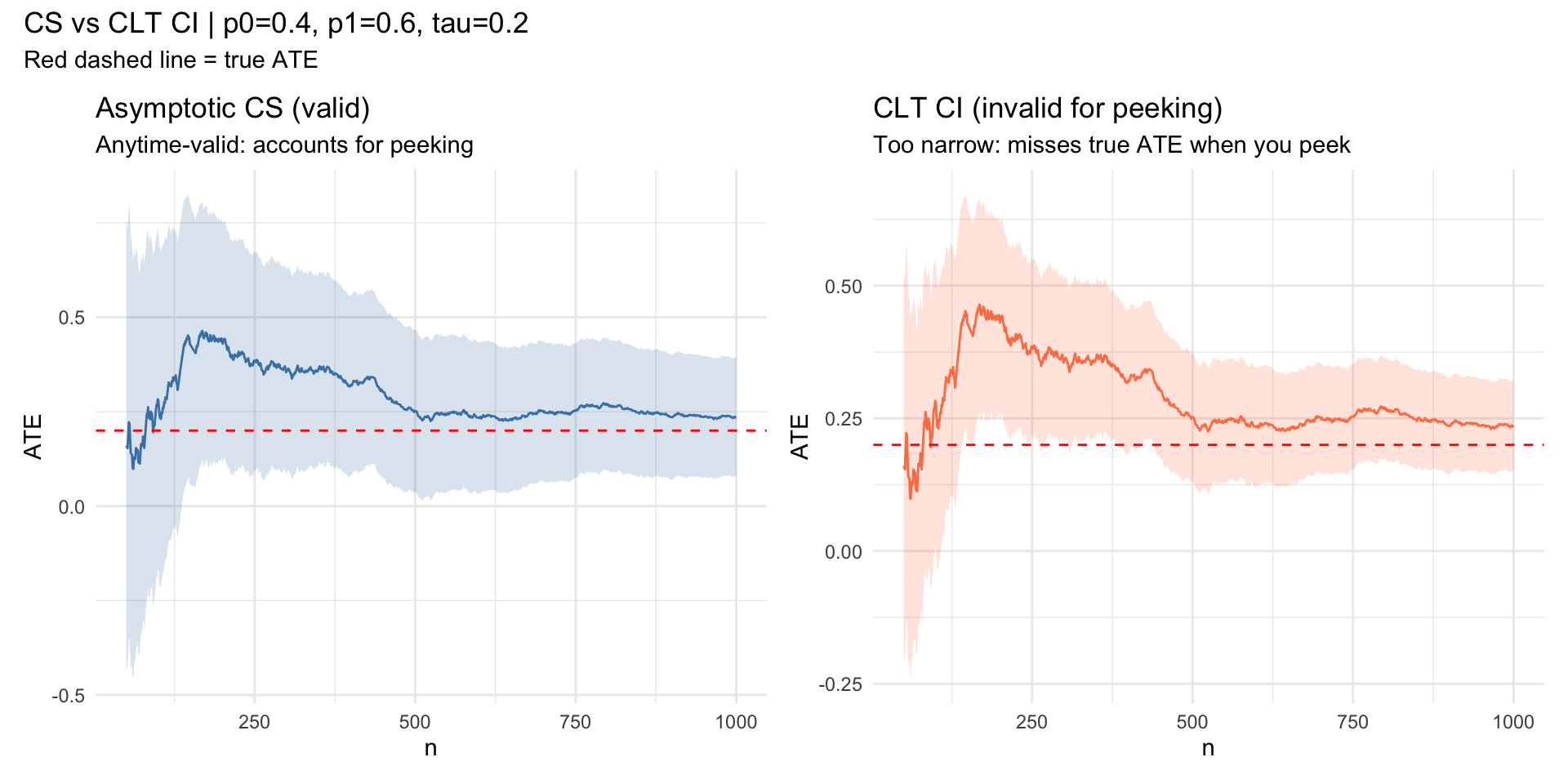
Confidence Sequences vs. CLT CI
Show simulation code
# --- Parameters ---
set.seed(7)
n <- 1e3; p0 <- 0.4; p1 <- 0.6; e <- 0.5
tau <- p1 - p0
Z <- rbinom(n, 1, e)
Y <- ifelse(Z == 1, rbinom(n, 1, p1), rbinom(n, 1, p0))
phi <- Z * Y / e - (1 - Z) * Y / (1 - e)
cs <- robbins_confseq(phi)
ns <- 1:n
mu_hat <- cumsum(phi) / ns
clt_hw <- qnorm(0.975) * running_sd(phi) / sqrt(ns)
df <- data.frame(
t = ns,
ate = mu_hat,
cs_lo = cs$lower, cs_hi = cs$upper,
clt_lo = mu_hat - clt_hw,
clt_hi = mu_hat + clt_hw
)[50:n, ]
p1_plot <- ggplot(df, aes(t)) +
geom_ribbon(aes(ymin = cs_lo, ymax = cs_hi), alpha = 0.2, fill = "steelblue") +
geom_line(aes(y = ate), color = "steelblue") +
geom_hline(yintercept = tau, color = "red", linetype = "dashed") +
labs(x = "n", y = "ATE", title = "Asymptotic CS (valid)",
subtitle = "Anytime-valid: accounts for peeking") +
theme_minimal()
p2_plot <- ggplot(df, aes(t)) +
geom_ribbon(aes(ymin = clt_lo, ymax = clt_hi), alpha = 0.2, fill = "coral") +
geom_line(aes(y = ate), color = "coral") +
geom_hline(yintercept = tau, color = "red", linetype = "dashed") +
labs(x = "n", y = "ATE", title = "CLT CI (invalid for peeking)",
subtitle = "Too narrow: misses true ATE when you peek") +
theme_minimal()
p1_plot + p2_plot +
plot_annotation(
title = sprintf("CS vs CLT CI | p0=%.1f, p1=%.1f, tau=%.1f", p0, p1, tau),
subtitle = "Red dashed line = true ATE"
)
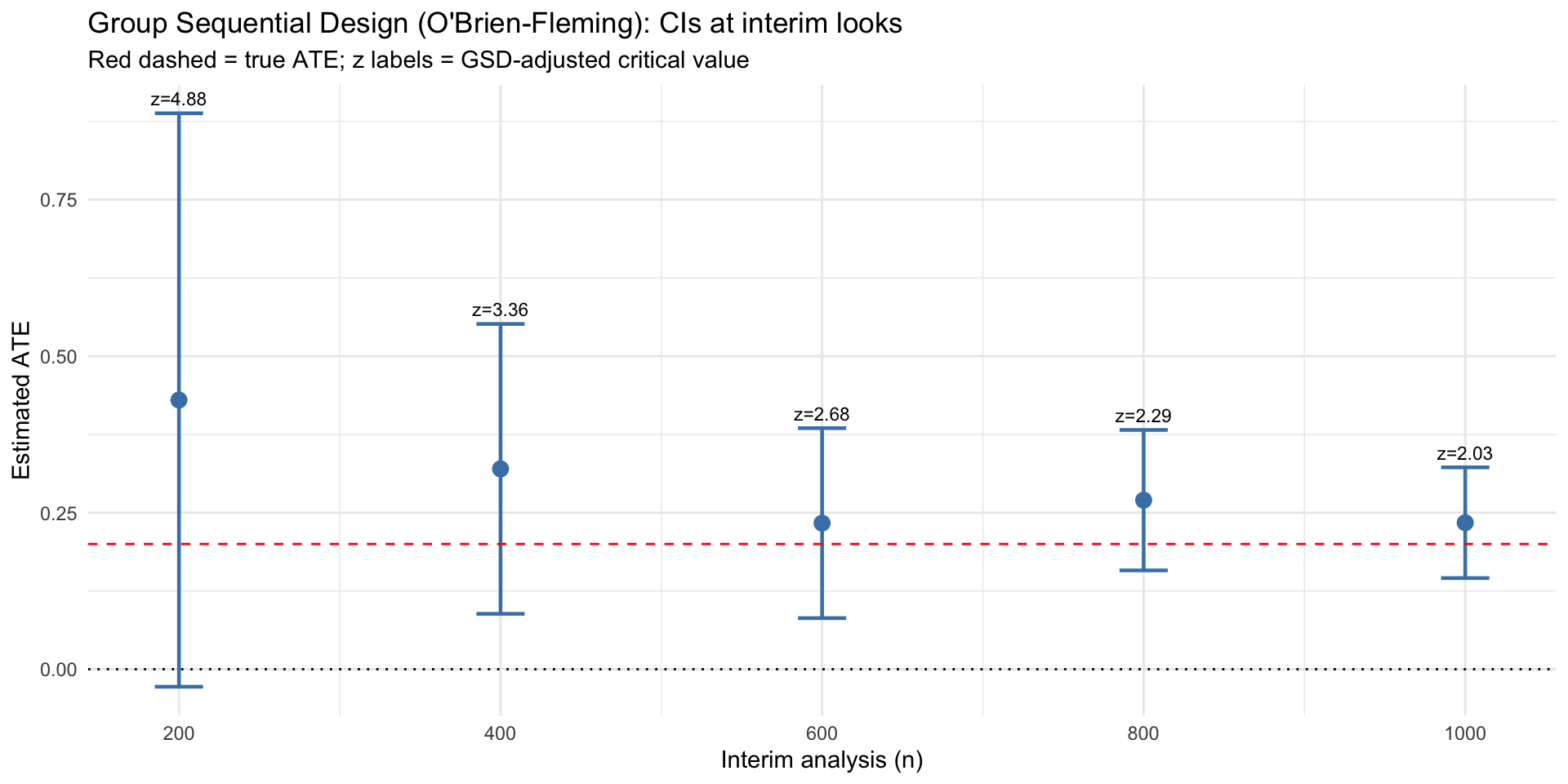
Group Sequential Designs in Action
Show simulation code
library(gsDesign)
# 5 equally-spaced interim analyses with O'Brien-Fleming spending
gs <- gsDesign(k = 5, test.type = 2, alpha = 0.025, beta = 0.1, sfu = sfLDOF)
interim_times <- c(200, 400, 600, 800, 1000)
gsd_df <- do.call(rbind, lapply(seq_along(interim_times), function(i) {
t <- interim_times[i]
x <- phi[1:t]
mu <- mean(x)
se <- sd(x) / sqrt(t)
z_crit <- gs$upper$bound[i] # GSD-adjusted critical value at this look
data.frame(t = t, ate = mu,
lo = mu - z_crit * se,
hi = mu + z_crit * se,
z_crit = round(z_crit, 2))
}))
ggplot(gsd_df, aes(x = t)) +
geom_errorbar(aes(ymin = lo, ymax = hi), width = 30, color = "steelblue", linewidth = 0.8) +
geom_point(aes(y = ate), color = "steelblue", size = 3) +
geom_text(aes(y = hi, label = paste0("z=", z_crit)), vjust = -0.6, size = 3) +
geom_hline(yintercept = tau, color = "red", linetype = "dashed") +
geom_hline(yintercept = 0, color = "black", linetype = "dotted") +
scale_x_continuous(breaks = interim_times) +
labs(
x = "Interim analysis (n)",
y = "Estimated ATE",
title = "Group Sequential Design (O'Brien-Fleming): CIs at interim looks",
subtitle = "Red dashed = true ATE; z labels = GSD-adjusted critical value"
) +
theme_minimal()